Curvature feature updates
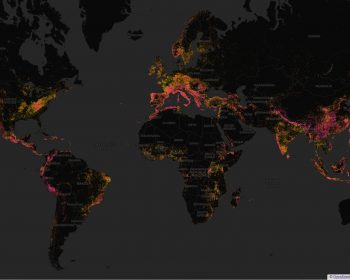
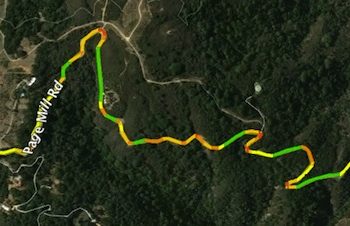
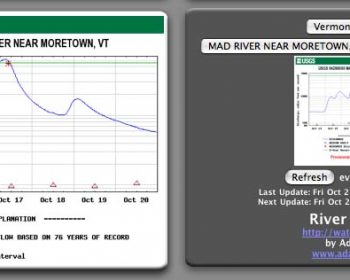
I recently launched several major new features for Curvature, my program that generates maps of the twistiest roads world-wide. I’ve had these in the works for several years and finally found the time to wrap them up.