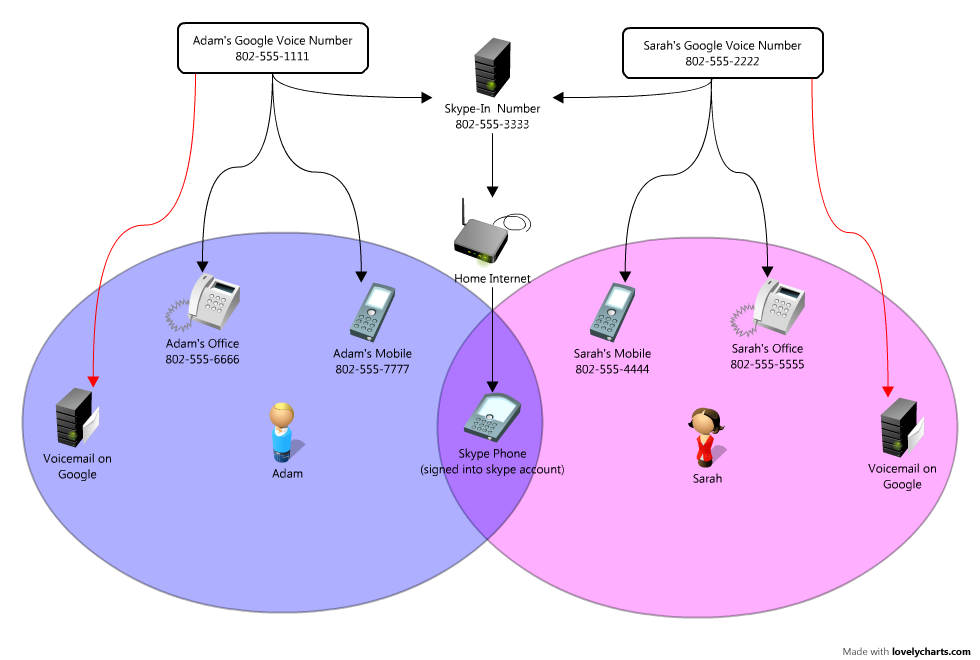
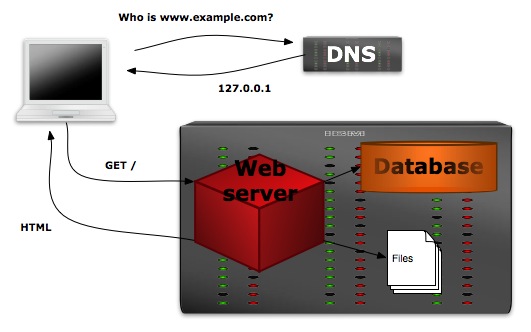
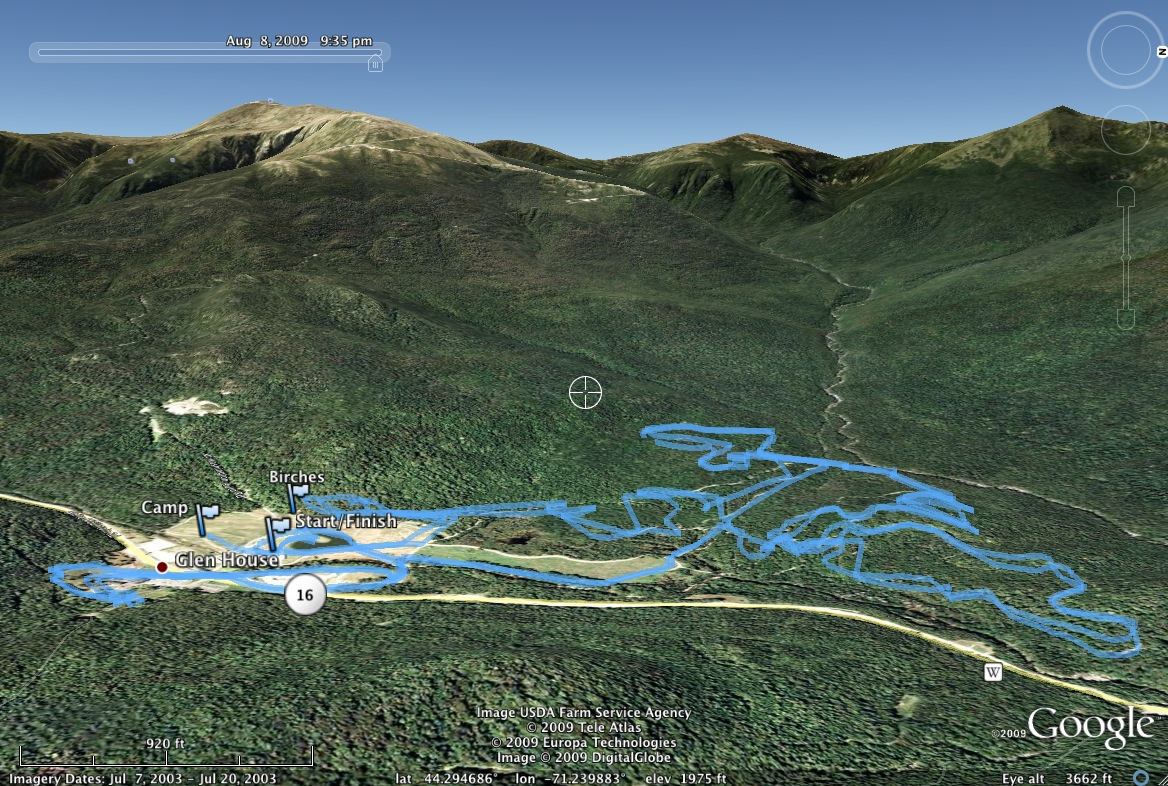
Sofa Table Complete

Over the course of the past year I built this cherry sofa table based on a design by Scott Gibson in Fine Woodworking’s “Furniture” book. All frame joinery is mortise and tenon, while the drawers use doweled rabbit joints. The finish is boiled linseed oil topped with 3 coats of…